

Your Data Isn't Ready for AI Agents
Most organizations want autonomous data management. Almost none have the foundation it requires.

I’ve spent the last four decades building and overseeing data infrastructure in one of the most regulated environments you can imagine: a federal law enforcement agency with thousands of staff, strict data sovereignty requirements, and zero tolerance for getting classification wrong.
So when industry analysts predict that 75 percent of all data engineering workflows will be automated by AI agents by 2029, I don’t feel excitement. I feel a very specific kind of concern. The kind you develop after watching three decades of automation promises crash into the same wall.
That wall has a name. It’s called: we don’t actually know what data we have.
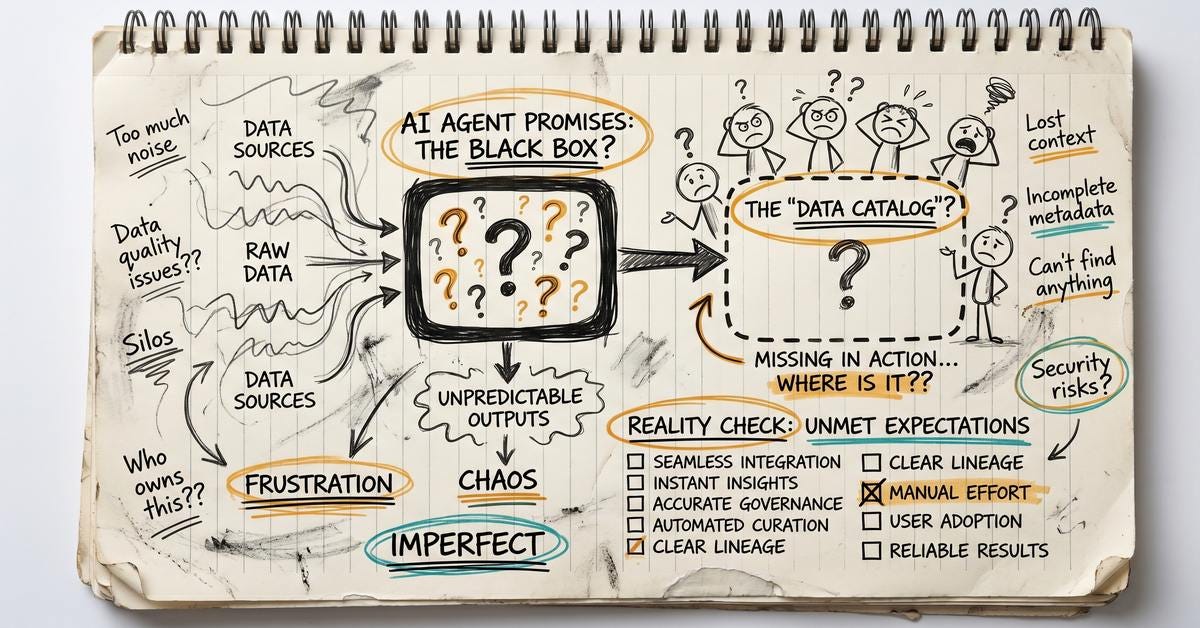
The promise sounds familiar
The current trajectory is clear: we’re heading toward a world where autonomous agents build pipelines, monitor data quality in real time, enforce governance rules, and self-heal when something breaks. Three types of agents are supposed to work together: specialized task agents for cleaning and transformation, orchestration agents coordinating across systems, and multi-agent systems that learn and optimize the whole thing.
The architecture is sound. The vision is compelling. And if you’ve been dealing with manual data pipeline maintenance for years, the appeal is immediate.
Here’s what the vision quietly assumes: that your organization already has a semantic layer. Machine-readable business definitions. A data catalog that reflects reality. Clear ownership for every data domain. Governance rules that are documented, not tribal knowledge.
In my experience, most organizations have none of this. Not partially. Not in rough form. Simply not at all.
What happens without the foundation
I’ve seen this pattern more than once: a large organization launches a data quality initiative with the best intentions. Identify problems systematically, measure them, fix them. Automated rules, clear metrics, repeatable processes.
The project stalls before it properly begins. Not because the technology fails — but because nobody can answer the most basic question: what data do we actually have, where does it live, and what does it mean?
There was no data catalog. No machine-readable definitions. No clear ownership. The quality rules had nothing to attach to. The team had to step back and inventory before they could measure. It sounds almost embarrassingly simple. That’s precisely why it matters.
Now imagine what happens when you skip that step entirely and deploy an autonomous agent instead. An agent that classifies data as non-sensitive when it doesn’t understand the classification scheme. An agent that restructures a pipeline because its model detected an anomaly that wasn’t one. An agent that adjusts access permissions based on patterns it inferred from inconsistent metadata.
In a hospital, that could mean patient records exposed to the wrong department. In financial services, regulatory violations. In law enforcement, where I’ve spent my career, it could mean classified information flowing into unclassified systems. These aren’t theoretical risks. They’re the predictable consequence of deploying autonomous decision-making on a foundation that doesn’t exist.
The real problem isn’t speed
Every automation wave I’ve lived through started with the same diagnosis: too much manual work, not enough speed. ETL tools were supposed to eliminate manual transformation. Self-service BI was going to free analysts from IT dependencies. DataOps promised to unify development and operations. Each time, the prescription was the same. Automate more. Move faster.
Each time, the organizations that struggled weren’t struggling with speed. They were struggling with understanding. They didn’t know what their data meant, who was responsible for it, or what “correct” looked like. More automation didn’t solve that. It amplified it.
AI agents are the most powerful amplifier yet. A rule-based system that runs on bad metadata produces one bad report. An autonomous agent running on the same bad metadata makes a thousand bad decisions per hour. And it makes them with a confidence no human would have, because it lacks the awareness of its own blind spots.
The question isn’t “which agent platform should we buy?” The question is: “Do we know our data well enough to trust an agent with it?”
For most organizations I’ve worked with, the honest answer is no.
Three things before your first agent
This isn’t about saying no to AI agents. They will transform data management, and they should. But the sequence matters, and it can’t be shortcut.
Start with the catalog, not the platform. You don’t need to inventory everything. Start with the three to five data domains that matter most to your critical processes. Five percent well-documented beats a hundred percent in a spreadsheet nobody maintains.
Architect human oversight in, don’t bolt it on. For every decision an agent might make, define three levels: where it acts autonomously, where it recommends, and where it stops and asks a human. In regulated environments, this isn’t optional. It’s the minimum viable architecture.
Define the outcome, not the tool. Not “we want AI in data management” but “we want to detect and resolve data quality issues in pipeline X within four hours instead of four days.” If you can’t state the outcome in one measurable sentence, the agent can’t deliver it either.
And one more thing that rarely makes it into the vendor presentation: metadata sovereignty. Who owns the business definitions and classifications your agent processes on a cloud platform? That question feels abstract until the vendor changes their API or discontinues the service. For organizations in Europe operating under strict data sovereignty rules, this isn’t a theoretical concern. It’s a strategic decision you make today whose consequences surface three years from now.
The uncomfortable truth
The organizations that will benefit most from AI agents in data management are the ones that need them least right now. They’ve done the unglamorous groundwork. They know their data. They have governance that works before it’s automated.
For everyone else, the path isn’t shorter because the tools got smarter. It’s the same three steps: know your data, organize your data, then automate. No agent makes the first step unnecessary.
The hard part isn’t the technology. It never was.
If you’re navigating this in your own organization, I’d like to hear how it’s going. What’s the biggest gap you’re seeing between the agent promise and your data reality? Hit reply.
I also write in-depth analysis in German on my blog: www.lezgus.de